
This is the first in a series of blog posts examining the evolution of web app architecture over the past 10 years. This post examines the forces that have driven the architectural changes and a high-level view of a new architecture. In future posts, we’ll zoom in to details of specific parts of the system.
The standard web application architecture suitable for many organizations has changed drastically in the past 10 years. Back in Heroku’s early days in 2008, a standard web application architecture consisted of a web process type to respond to HTTP requests, a database to persist data, and a worker process type plus Redis to manage a job queue.

Now, in 2018, a website (or mobile app) is the primary way many companies interact with customers. Technology is inextricably woven into the fabric of almost every business. As technology is being tasked to do more for a business, we as developers need new breeds of architectures to start from for the modern web app.

The Change Drivers
How have users’ expectations of computers, phones, and software changed in the past decade? What are the drivers of this change? And what do those changes imply for a new web app architecture?
Snappier Web Experiences
The constraints of the web’s request / response pattern led to poor user experiences. Imagine if every installed application on your computer had to re-render the entire screen whenever you clicked something! And now—to simulate the web’s latency—add the restriction of using a computer from twenty years ago but running today’s software. This is what much of the web user experience is like. It’s shocking that we put up with it as much as we do.
Our desire for richer, more interactive, and lower latency web experiences has driven the popularity of single page apps and the JavaScript tools required to build them. Use of convenience libraries like jQuery gave way to libraries like Backbone.js and Knockout.js that finally supported the creation of a cohesive, maintainable app that runs in the user’s browser.
The next generation of libraries—where we are now in 2018—including React, Angular, Ember, and Vue, were born out of our experiences with the first generation plus the exploding popularity of Node.js (here, as a build tool) and rapid improvements to JavaScript (or maybe more accurately, ECMAScript with versions ES2015, 16, 17, etc).
So what architectural changes do we need to make to allow our web application to support single page apps? First, we need a way to more efficiently deliver JavaScript to the user’s browser. Single page apps include much more JavaScript (and possibly more images, videos, CSS, and HTML) than we had previously sent to the browser. Second, it means we need a publicly exposed API from which the single page app can get its dynamic data.
So here’s the list of new concepts we’re going to add to our architecture:
- Content Delivery Network -- effectively a global network cache that can deliver JavaScript, HTML, CSS, and images to the user’s browser faster than our web server can.
- API Gateway -- a publicly exposed API from which the single page app can securely request the data it needs.
Smartphones
Today most of us expect to find a mobile app for any product or service we want to interact with—or at least a web site that works well on our mobile devices. We now use mobile devices for so many things we could do only in the desktop browser just ten years ago—or even new things we could never do in the desktop browser, like receive a notification based on location, scan a digital coupon, or track a workout. And this trend doesn’t look like it’s going away: in 2011, 10% of the world’s population were smartphone users, and now in 2018, a third are smartphone users. In many countries like the United States, Sweden, and South Korea, 70% of the population is using smartphones.
The iOS App Store and Android Market (now Google Play) appeared in 2008 and ushered in the era of ubiquitous native mobile apps as mobile web browsers hadn’t and still don’t (although they are getting better and better) allow for the same user experience that a native app does.
So what do we need to support a native mobile app in our architecture? We need a way for the app to communicate with our servers—to receive a push notification, receive a digital coupon, or save the GPS data for a user’s workout. Fortunately, we can use one of the concepts we added to support single page apps: an API Gateway.
API as a New UI
It seems that every company wants its own API now. Obviously companies like Heroku, GitHub, and Amazon Web Services whose customers are developers, need an API, but now many companies whose customers aren’t developers — like Bank of America and Macy’s — have APIs. ProgrammableWeb’s API Directory lists over 19,000 public APIs that companies or other organizations have built, most of them from companies whose primary customers are not developers. All these APIs are a kind of new user interface for developers.
An API opens your product up to endless possibilities of creative extension by millions of software developers. Google Maps, Twilio, and Braintree probably didn’t think about ride-sharing as a use case for their APIs, but Uber and Lyft wouldn’t have been possible without a mapping, SMS, and payment API.
An API also provides a standard point of integration with your product. Often the electrical socket analogy is used to explain this. Without a standardized electrical socket, we would have to manually wire each new device we get into our home’s electrical system. The electrical socket gives us a standard interface between a device and the electrical grid. Similarly, because there are common standards for APIs, like REST over HTTP using JSON content type, we as developers need less time and proprietary expertise to integrate two disparate systems.
As you might have guessed, this API can use the same architectural concept we added in the last section: an API Gateway.
Streaming Data (And Lots of It)
The software we create is producing data at an exponentially growing rate. And we are demanding much more from that data. We want data not only to build the user’s web or mobile experience, but we want it for reporting, for informing A/B tests or blue/green deploys, for user experience studies, for billing, and for compliance. And often we need a real-time view of that data with the flexibility to create different views to support evolving business requirements.
The “data firehose” has emerged as a metaphor to describe harnessing all of this moving data. We need a data firehose to help move this data around in an organized way. It could be to move data from the point of production to storage, to allow internal services to communicate with each other, or to send real-time data to analysis and visualization tools.
So what do we need to add to our architecture to manage, observe, analyze, and visualize streams of data?
- Apache Kafka -- a tool that can manage large streams of data reliably and to which data producers and data consumers can easily attach themselves
- AWS S3 / Google Cloud Storage -- effectively unlimited and redundant storage for all the data
- AWS RedShift / Google BigQuery -- a data warehouse tool to organize the data and make it queryable quickly
- Heroku Dataclips / Metabase / Looker -- data query and visualization tools that are simple to connect to the data warehouse and easy to start using
Adaptability
Ever-increasing complexity (i.e. business complexity, requirement complexity, software becoming more mission-critical to businesses, increased real-time expectations of users, growing data volumes, etc.) means developers need to build and operate more adaptable systems.
An increasingly popular way to build a more adaptable system is to compose it from many small, discrete services. Call this technique what you want—microservices, distributed systems, service-oriented architecture, or even functions-as-a-service—the important concept is the composition of separately-maintained and deployed software components to form a single system.
Building new functionality as separate services instead of within a monolith allows for easier separation of concern. As a developer, I can keep fewer concepts in my head while building or maintaining smaller services. As an engineering manager, my team can work on more in parallel. To be clear, this technique doesn’t come without pitfalls. Check out Ryan Townsend's blog post on his company’s journey of deconstructing a monolith into services.
And Don’t Forget Scale
Clearly, the need for scale is not new in 2018, but the addition of all these new architectural components makes scaling more difficult than it was a decade ago. Previously we could manage most of our scaling needs with three levers: horizontal scaling of web dynos (Heroku’s lightweight container technology), horizontal scaling of worker dynos, and vertical scaling of PostgreSQL. Now we have dozens of levers to worry about. And further compounding the scale problem is the relentless growth of internet users. Half the people on our beautiful blue marble have access to the internet!
This is one area where PaaS and managed services show their value. The good ones reduce the number of levers you have to worry about to scale your system, letting you focus more on creating functionality for your users and less on operations and infrastructure.
Bring It All Together
So let’s look at all the components we need to add to our architecture:
- Content Delivery Network -- effectively a global network cache that can deliver JavaScript, HTML, CSS, and images to the user’s browser faster than our web server can.
- API Gateway -- a publicly exposed API from which the single page app can securely request the data it needs.
- Apache Kafka -- a tool that can manage large streams of data reliably and to which data producers and data consumers can easily attach themselves
- AWS S3 / Google Cloud Storage -- effectively unlimited and redundant storage for all the data
- AWS RedShift / Google BigQuery -- a data warehouse tool to organize the data and make it queryable quickly
- Heroku Dataclips / Metabase / Looker -- data query and visualization tools that are simple to connect to the data warehouse and easy to start using
And the two new concepts we need to think about:
- Service-oriented architecture for adaptability
- Scalable-first design so that scaling is a normal operations activity, not a herculean one at 2am
Let’s look at our new architecture from a high-level. All of the new components we discussed have been incorporated into a single system.
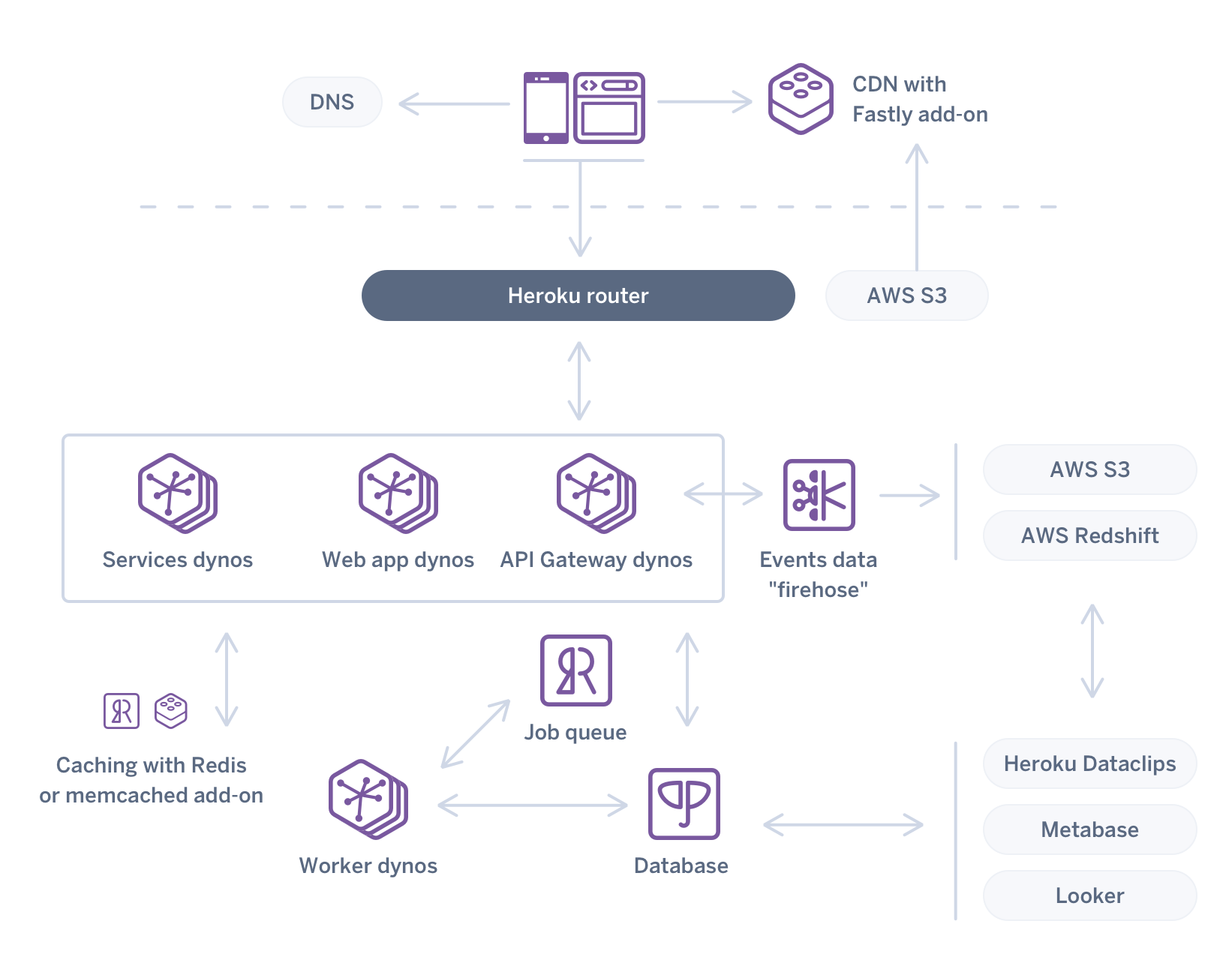
Compared to the version from 2008, it looks like a lot to build and manage, right? It could be, if you try to build and manage it all yourself. The truth is that using a PaaS like Heroku makes deploying and managing something like this much easier than building it yourself on an IaaS (or your own data center [shudder]).
Looking to the Future
For sure, we still have many open questions. How do the dynos discover each other and communicate between themselves? What gets served from the CDN and how does it get there? How does Kafka write data to S3 or RedShift? How do code deploys work? How does CI/CD work? How do we monitor the health of all the components? What security concerns do we have to think about?
In follow-up blog posts, we’ll zoom in to specific parts of this system and show you how to deploy them to Heroku. Until then, I hope this high-level architecture serves as a guide to the primary concepts many organizations need to think about as they’re building a web application in 2018.
Many thanks to those who helped me write this post: Vik Rana, Charlie Gleason, Jennifer Hooper, Scott Truitt, Matt Schaar, Jon Mountjoy, Jon Byrum, Michael Friis, Hunter Loftis, Stephanie Chung, and Jonathan Fulton’s Web Architecture 101 post. Your reviews, discussions, ideas, inspiration, grammar help, drawings, and typo catches are greatly appreciated.